Time to change a business
For today’s Gedankenexperiment we’re helping a large company make a tricky move.
We’re at ACME, a company that has been around for about 40 years, has a ~5 million customers and holds credit card data and health information on all of them. They’ve been running on self hosted infrastructure but are finding it hard to hire new engineers to work in this environment. As a silver bullet for all engineering woes, it has been decided to throw money at the problem and move all of the workloads to cloud. (Before you put your hand up, no, we are not being asked our opinion on this).
We are going to ignore all the technology and architecture today and focus on creating a business path to making this possible using the magic of risk management.
Risk management is looking into a crystal ball, figuring out what the future might look like and take measures now to avoid any of the bad stuff later (or at least have a plan to deal with it if it does happen regardless). The goal is to create a business case for a plan with some reasonable chance of actually succeeding.
The steps are as follow,
- List out all the bad things that might happen (risk identification)
- For each bad thing, figure out what the likelihood is of the bad thing happening
- For each bad thing, figure out how much it would hurt (impact) if the bad thing happened
If we know the likelihood and impact of a risk, we can rate it using a risk rating matrix. This will be different everywhere, but today we’re using this one.
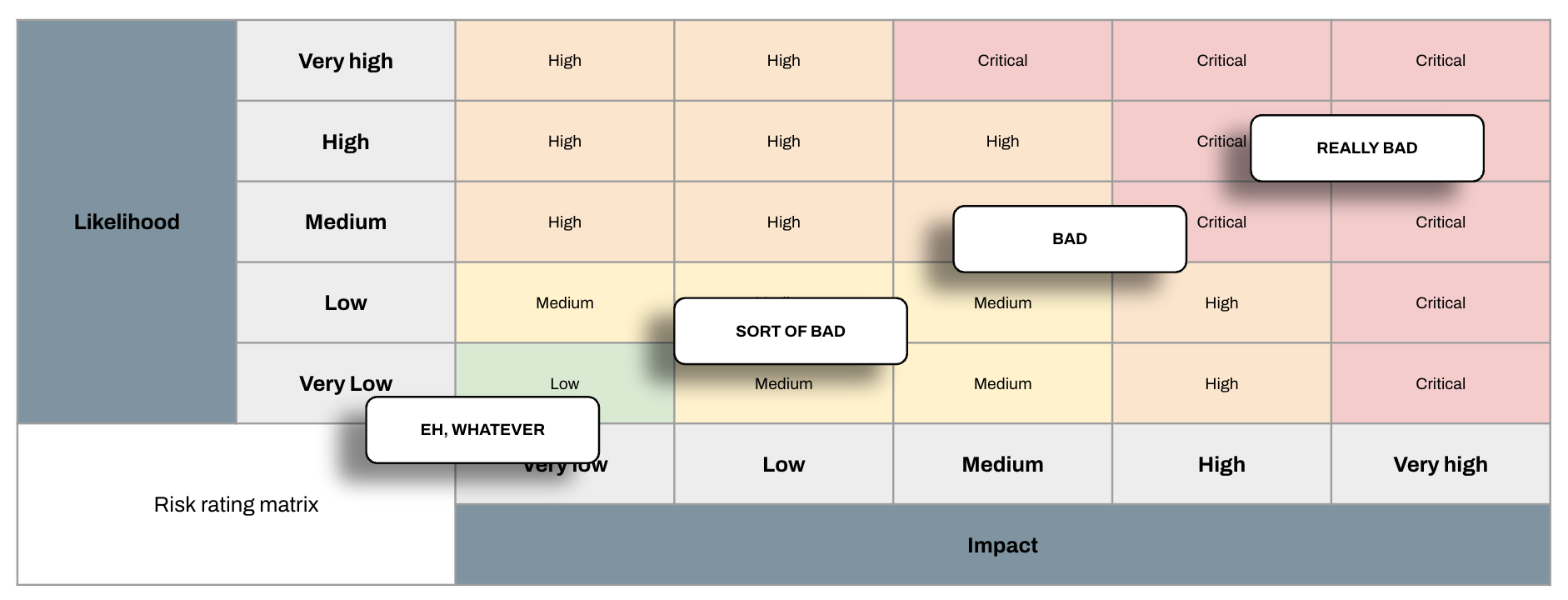
As you can see there is a really steep drop-off after risks get below MEDIUM here. Any risk that is LOW falls into the bucket of things the company doesn’t care about anymore. The risk management way to express this is to say that the risk is within tolerance or within the organisation’s risk appetite.
Let’s take our really long list of bad things that could happen, and rate all of them, dropping them onto this matrix.
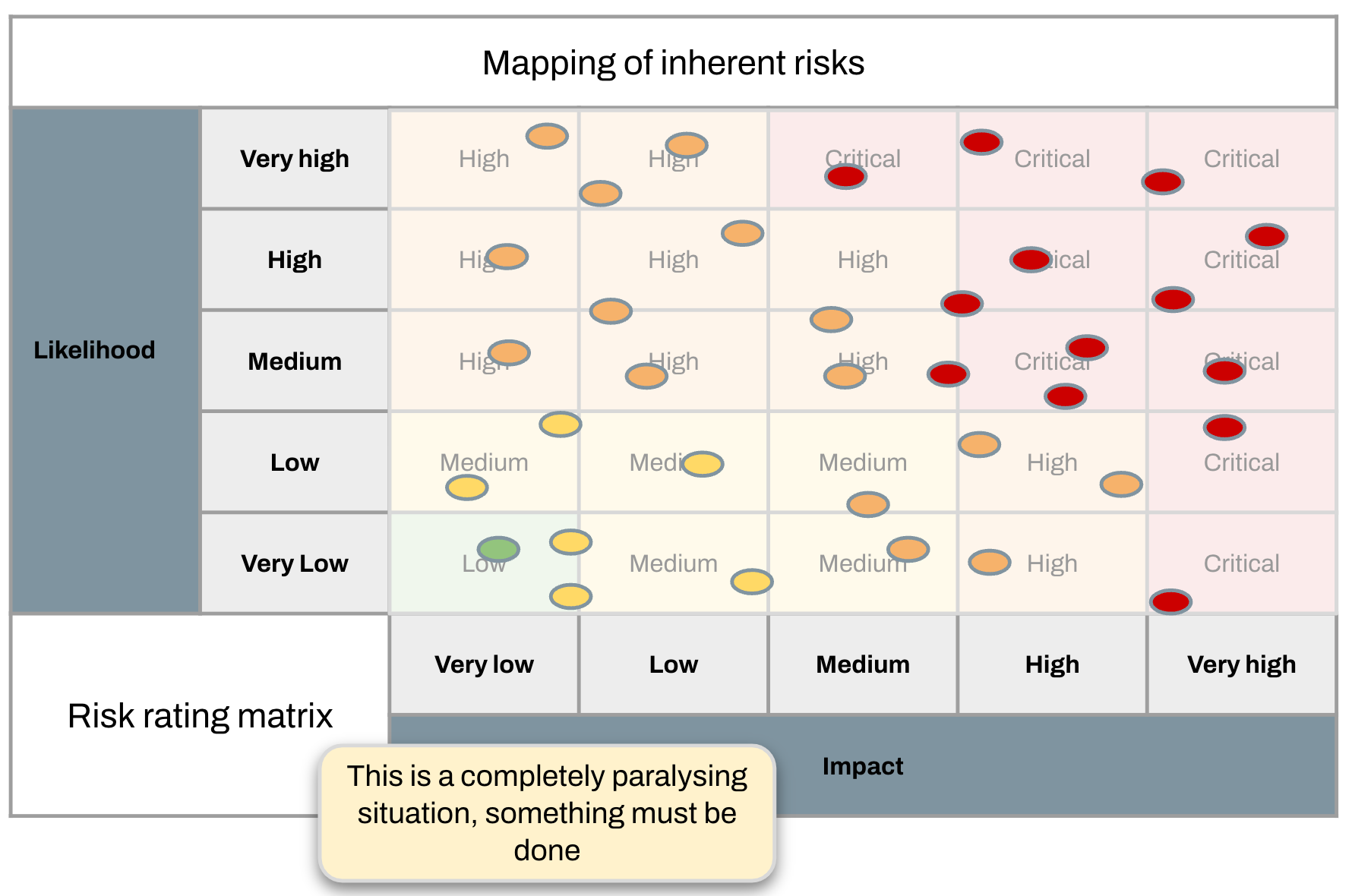
This is what the future looks like if we don’t do anything about it. There are a lot of bad things, the bad things are very, very likely to happen (risk materialisation) and they will hurt a lot when they do (risk impact).
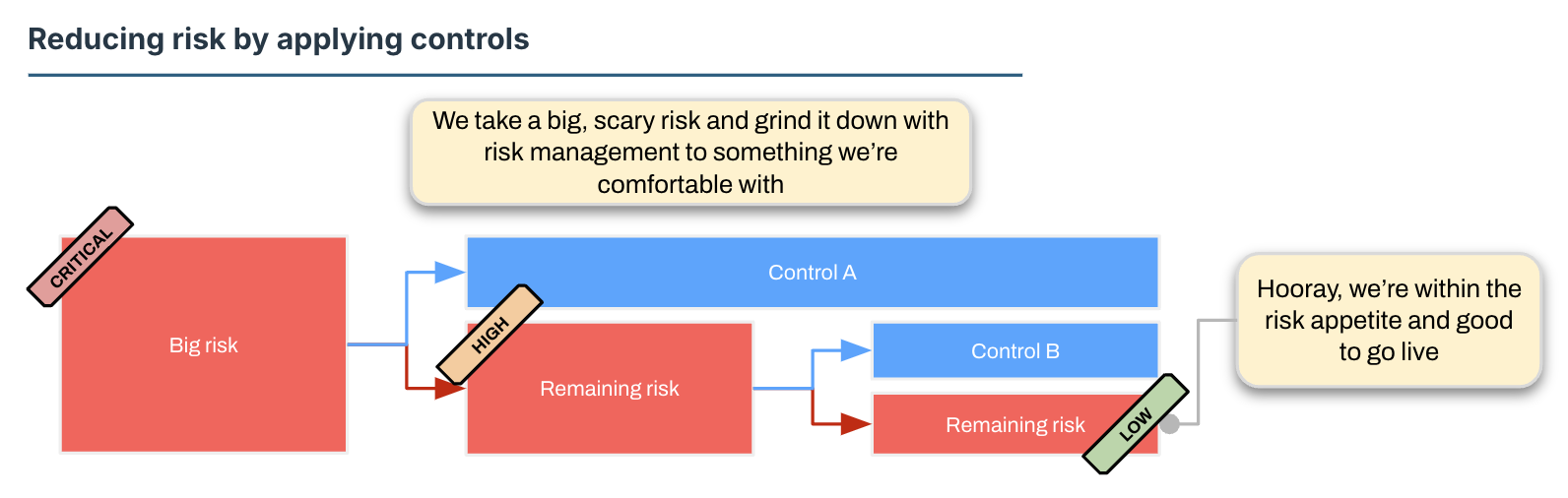
Now what we’re going to do is look at each of these risks in turn and reduce either the likelihood or impact. You can also eliminate risks, but for the high level ones you can generally only do that by eliminating a business function. Let’s ignore that for now.
The goal of this exercise is to move the risk’s position (rating) on the example risk rating matrix below to a lower value so the business is happy with it (risk acceptance). You might start with a Critical risk (e.g. some consequence of running financial applications on public infrastructure) and then keep layering on controls until this risk becomes Low.
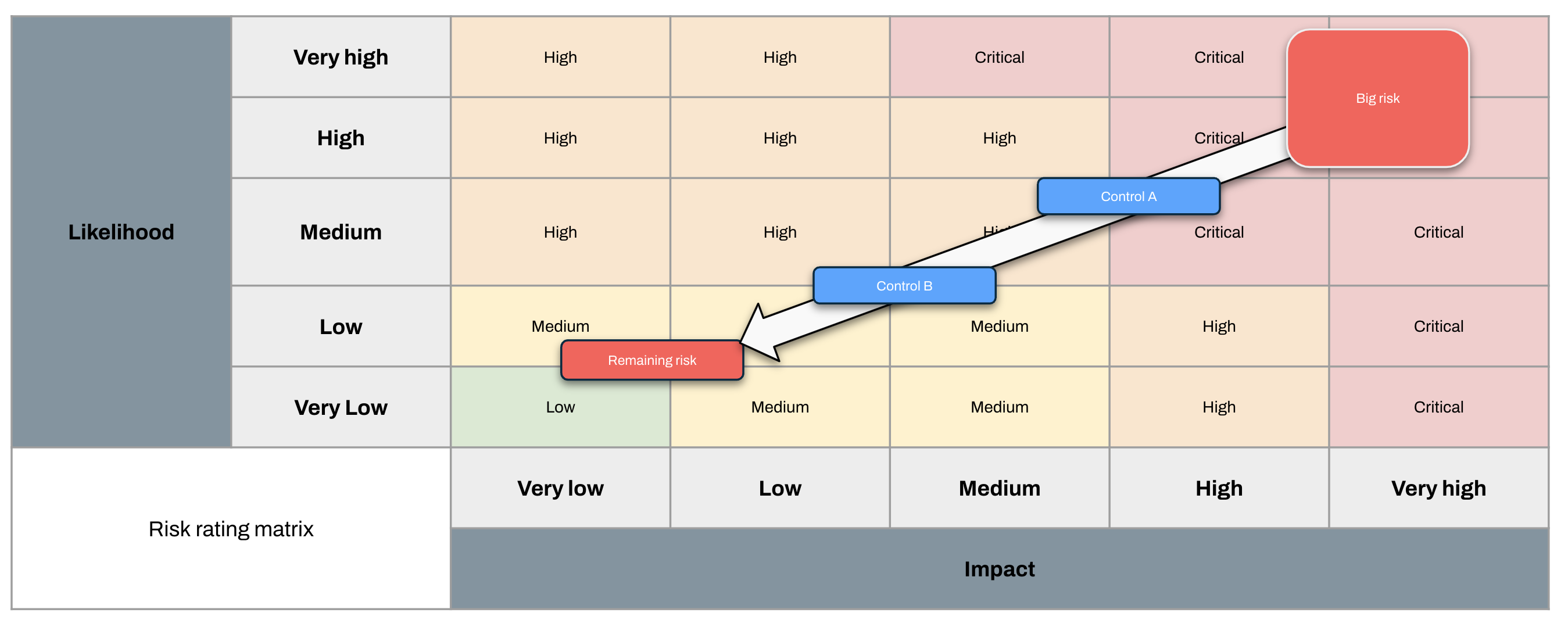
By doing this for all risks we change our overall risk position and bring everything into ACME’s risk tolerance.
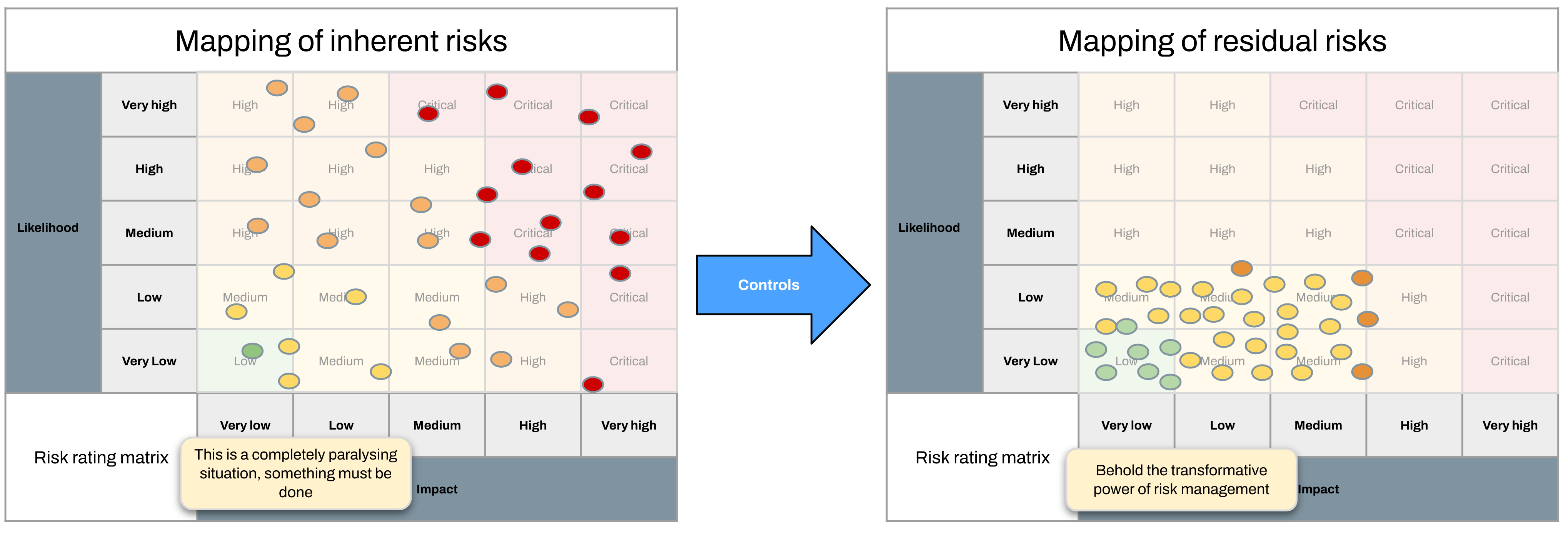
This risk position based on neatly categorised and managed risks is often used to inform decisions, drive investment priorities, and so forth because everything can be dropped into a spreadsheet, mapped to various frameworks by Big-4 consulting firms, and presented back with neat charts and heatmaps which give everyone a nice fuzzy feeling.

Congratulations, you’ve risk-managed your path to moving to cloud! It is all sunshine and rainbows from here on out.
Where things go off the rails
Everything is ticking along nicely at ACME until one day an engineer receives an alert that a storage quota has been exceeded in the test environment for the marketing department.
As part of the cleanup, this engineer notices that there is what appears to be personal information present in this marketing environment. “Huh”, this engineer thinks to themselves, “this shouldn’t be here” and flags it with data security.
Further investigation reveals that test environments are built off of a common stack and end up sharing temporary storage space. This creates a shared link between marketing and a customer service workload test environments. Engineers for this customer service workload have been replicating production data to test environments to troubleshoot an issue and that data has leaked through the shared testing infrastructure.
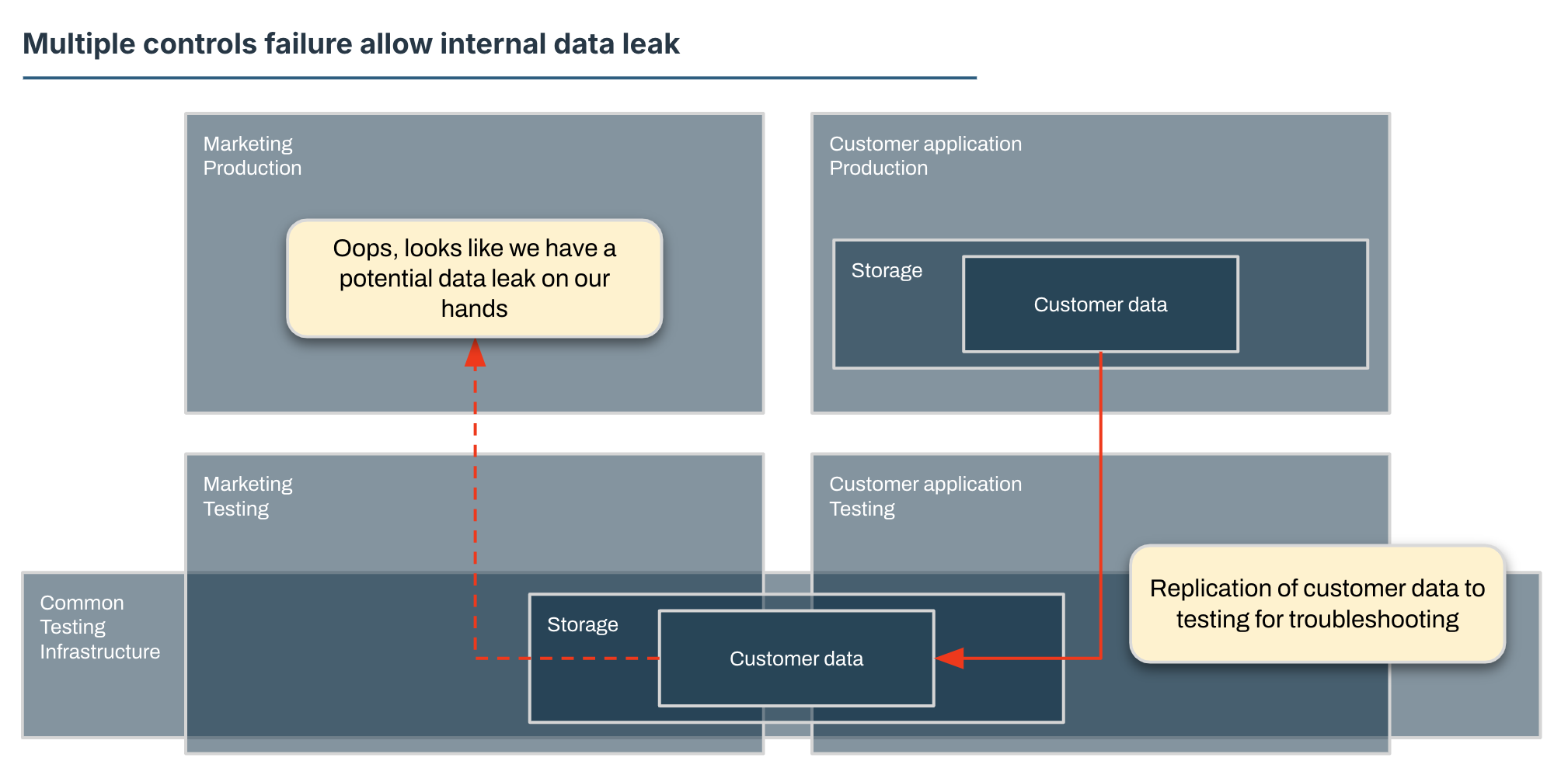
So how did we get into this situation? We have listed Data Leak as a top level strategic risk, with a whole range of controls against it. This is very serious design work, we have spreadsheets and everything.
Well, it appears that one of these controls (keeping production data in production only) is not working as well as we intended it to. This control is, let’s say, Partially Effective so not really doing what we want it to do. We’ll have to re-assess what that means for us.
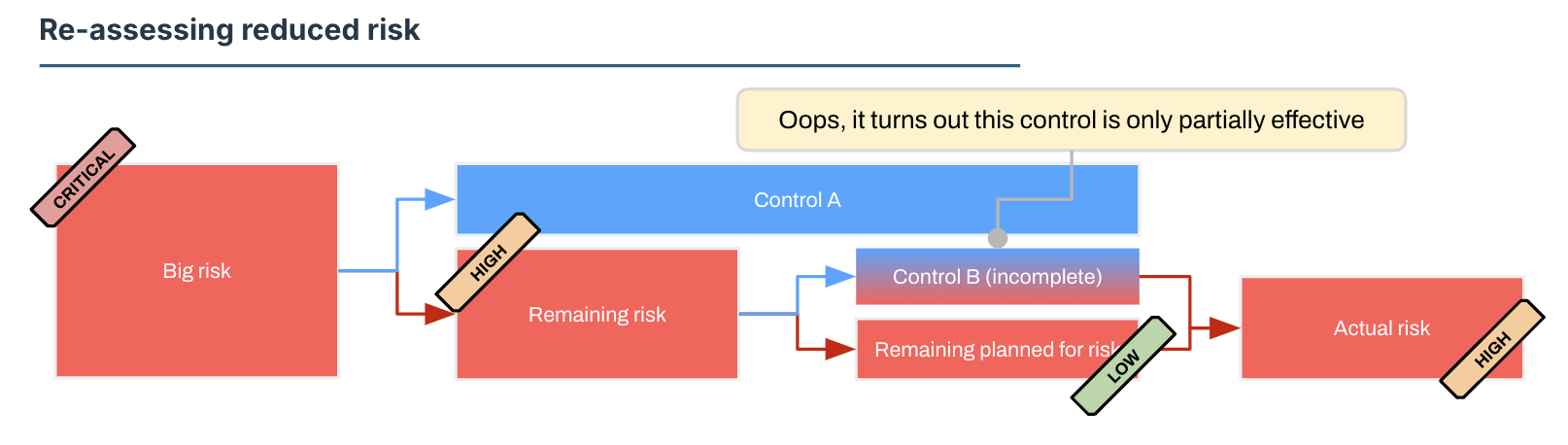
It looks like the risk we’re actually carrying (our residual risk) is significantly higher than we thought it was, and we need to reposition.
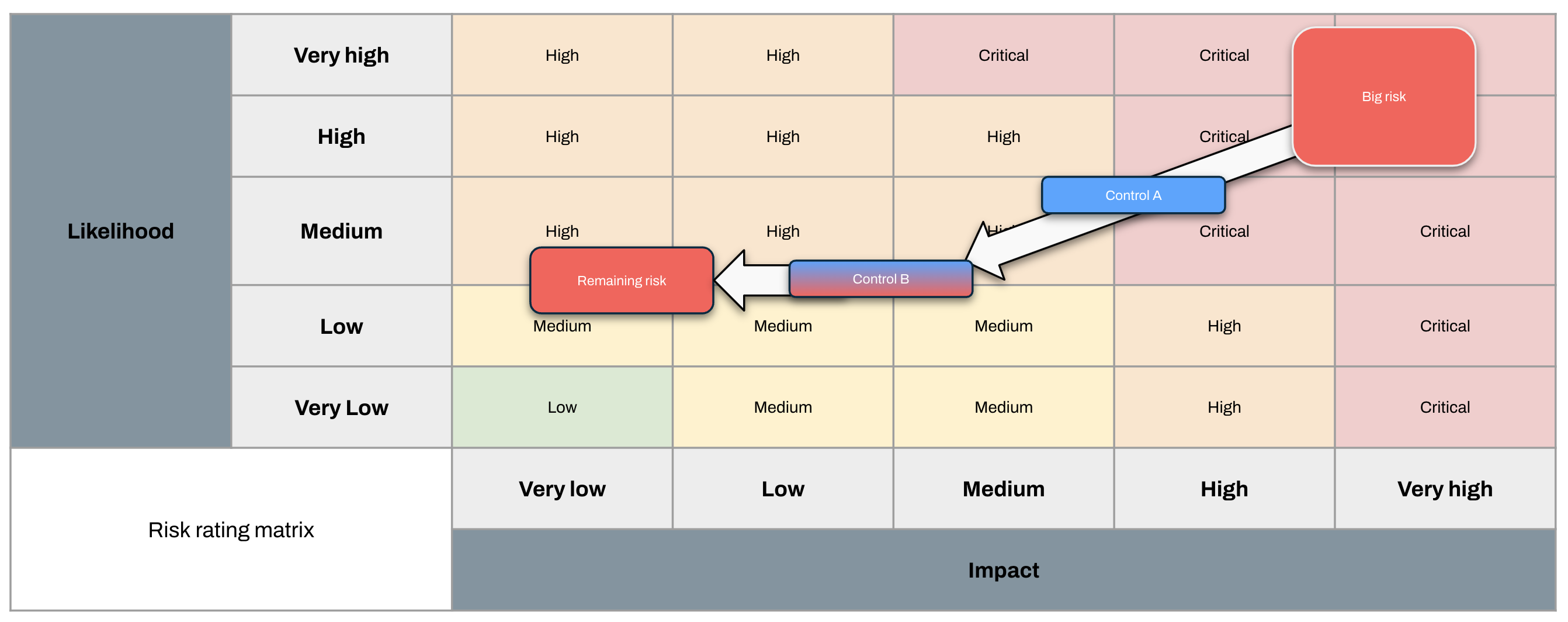
It’s immediately clear that Something Must Be Done to bring this updated risk into our risk appetite. We could actually implement the control properly so data doesn’t get replicated to test environments, we could isolate test environments, or we could eliminate the Marketing function so data can’t leak there. Plenty of options to choose from.
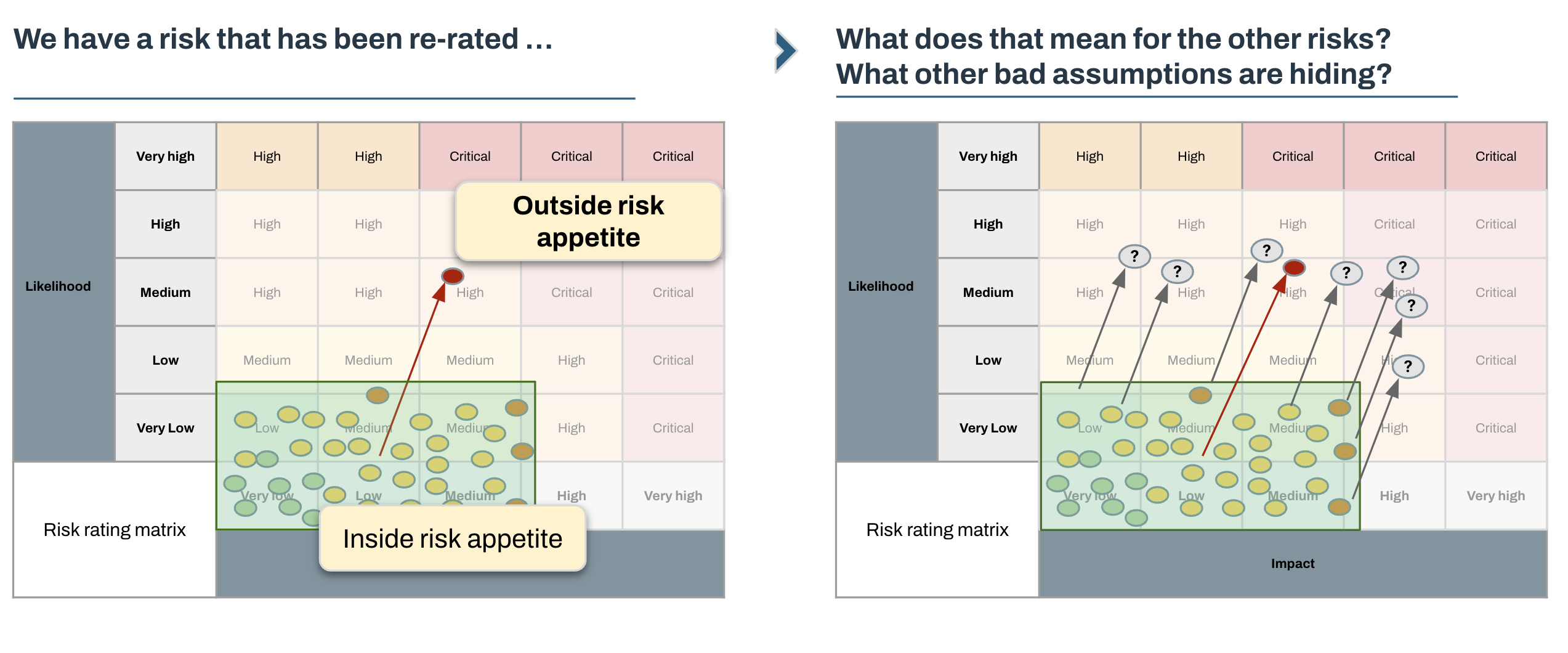
Finding out that controls are not doing what they are supposed to be doing opens up a whole new can of worms. Once you open it you will see people around you suddenly start to get very, very nervous. Put yourself in their shoes - introducing uncertainty means that some of the operating assumptions might suddenly turn out to be invalid and potentially kick off a cascade of actions.
We need to provide answers to most of the following,
- Do any of these other risks have weak or non-existent controls?
- How can we know? Do we have any assurance?
- If there are detective controls that turn out to be ineffective, how do we know if associated risks have materialised?
- If there are other weak controls, where do these risks end up after re-rating them?
- If we re-rate risks, how does our risk position shift?
- Does this put ACME outside of its risk appetite?
- If we’re outside of our risk appetite, what are the options for remediating that?
- How much will these options cost?
- Which options will have the greatest impact?
- Have we missed anything?
Our next step is to remove this uncertainty.
We can rephrase our questions above to three key ones,
- What is happening? - Are any other controls weak? Have we missed anything?
- So what impact does that have? - How far outside of our risk appetite are we?
- Now what do we do? - What can we do about it? What are our options?
What? Are any other controls weak?
The answer is almost always yes, and what we’re interested in is a matter of degrees. Designs on paper can be perfect, but reality is messy. A good starting point is to identify what we are basing our assurance on.
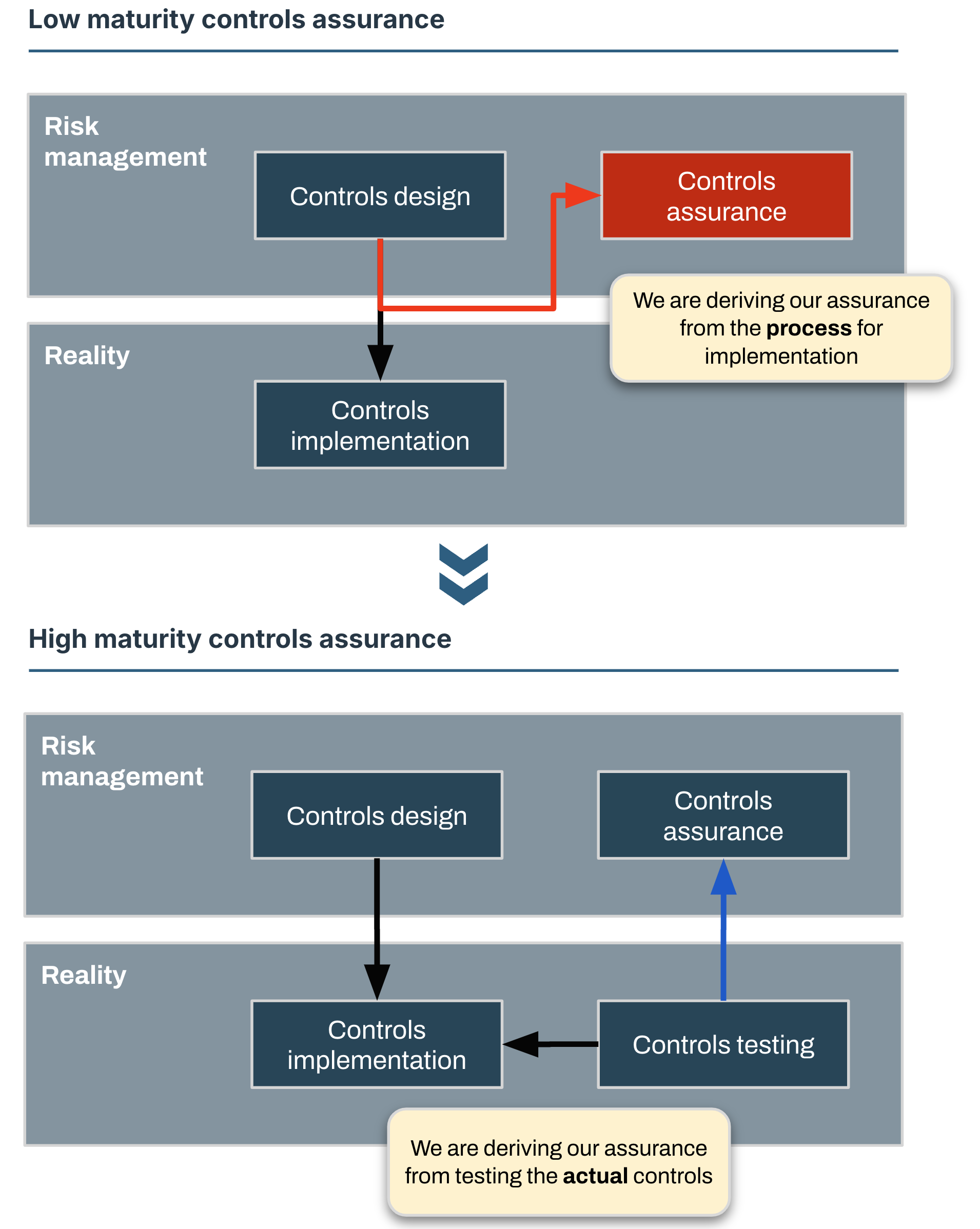
For example, say we have a policy for Endpoint Detection and Response (EDR) with a control that states all systems must have an EDR agent. The wording for this control might not be particularly precise, but we understand the intent.
If we derive our assurance from process, we might check that all system base or installation images have an EDR agent and confidently state that yes, we have 100% coverage of EDR for all systems. This might even hold true, but it does not match the intent of the control. The intent is for agents to be active and up to date on all systems and we don’t know that unless we test for it.
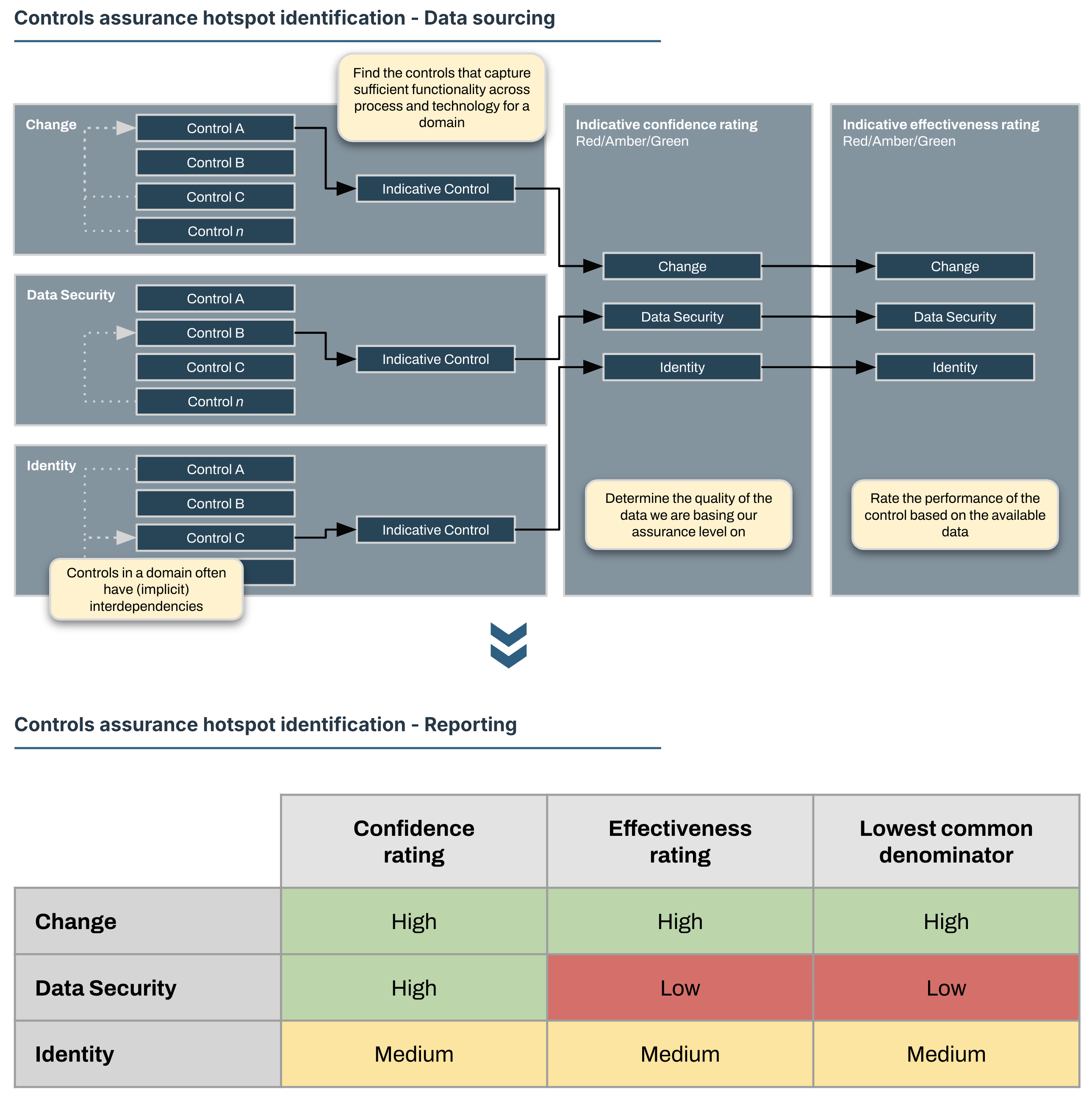
Assuming there are controls in place, and that the controls are positioned correctly against control objectives, we can go through each of these controls and verify the level of assurance we have for their coverage and efficiency.
I don’t like doing this. Controls frameworks can run into hundreds of controls, so this exercise will be time-consuming, tedious, prone to manual errors and not particularly effective.
I recommend picking only a single key control for each area or domain of interest. This will give you a good idea of the overall health of the control environment by highlighting hotspots and clearly identifying areas of concern that might need further investigation.
So what? What is the impact?
If we view uncertainty by combining the effectiveness measurement and the confidence we have in that measurement, we can project the range that uncertainty represents on the risk rating matrix.
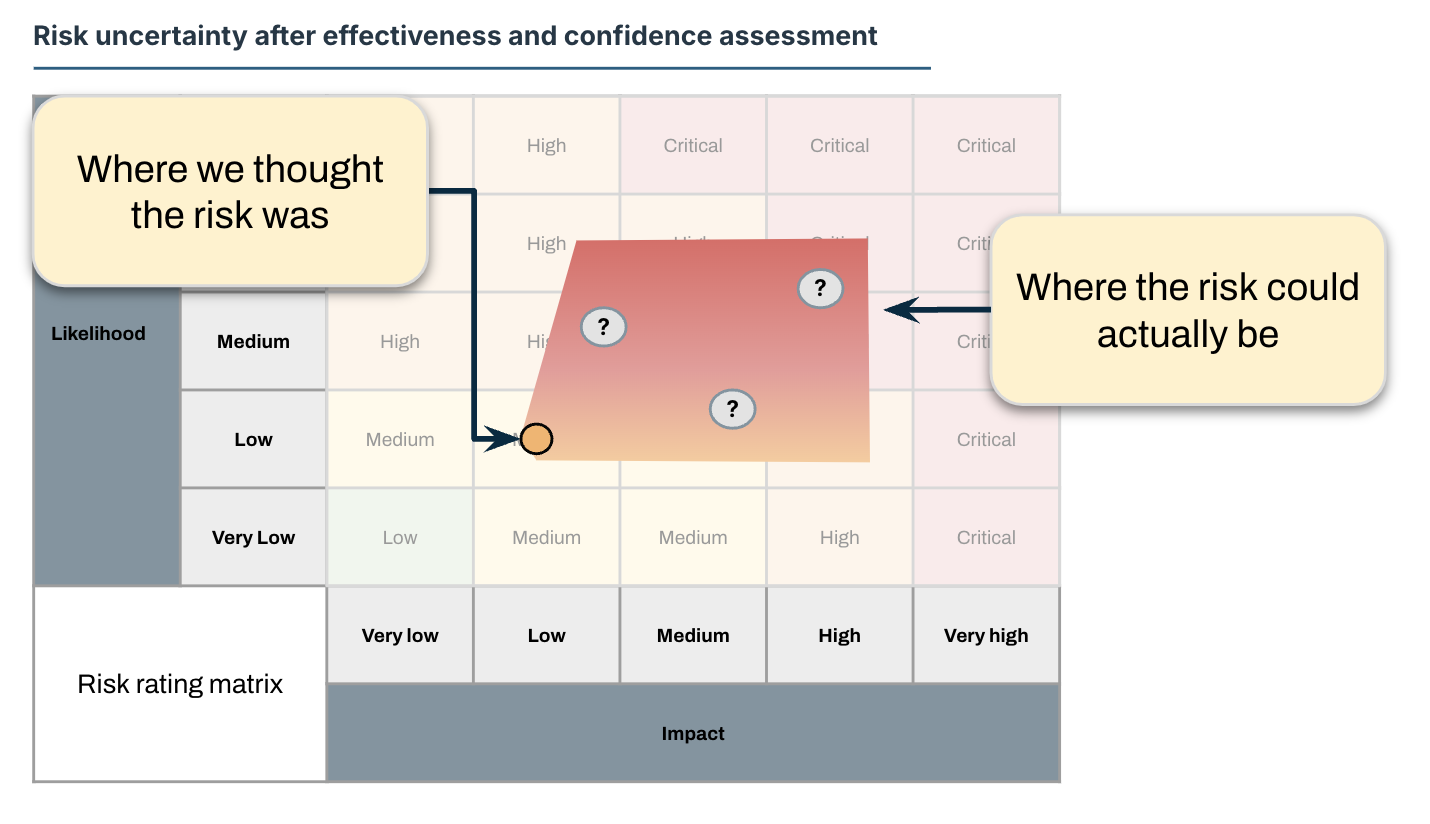
We can take a slightly more rigorous approach by taking the Lowest Common Denominator of the effectiveness measurement and confidence assessment, and adjust the affected risk ratings accordingly.
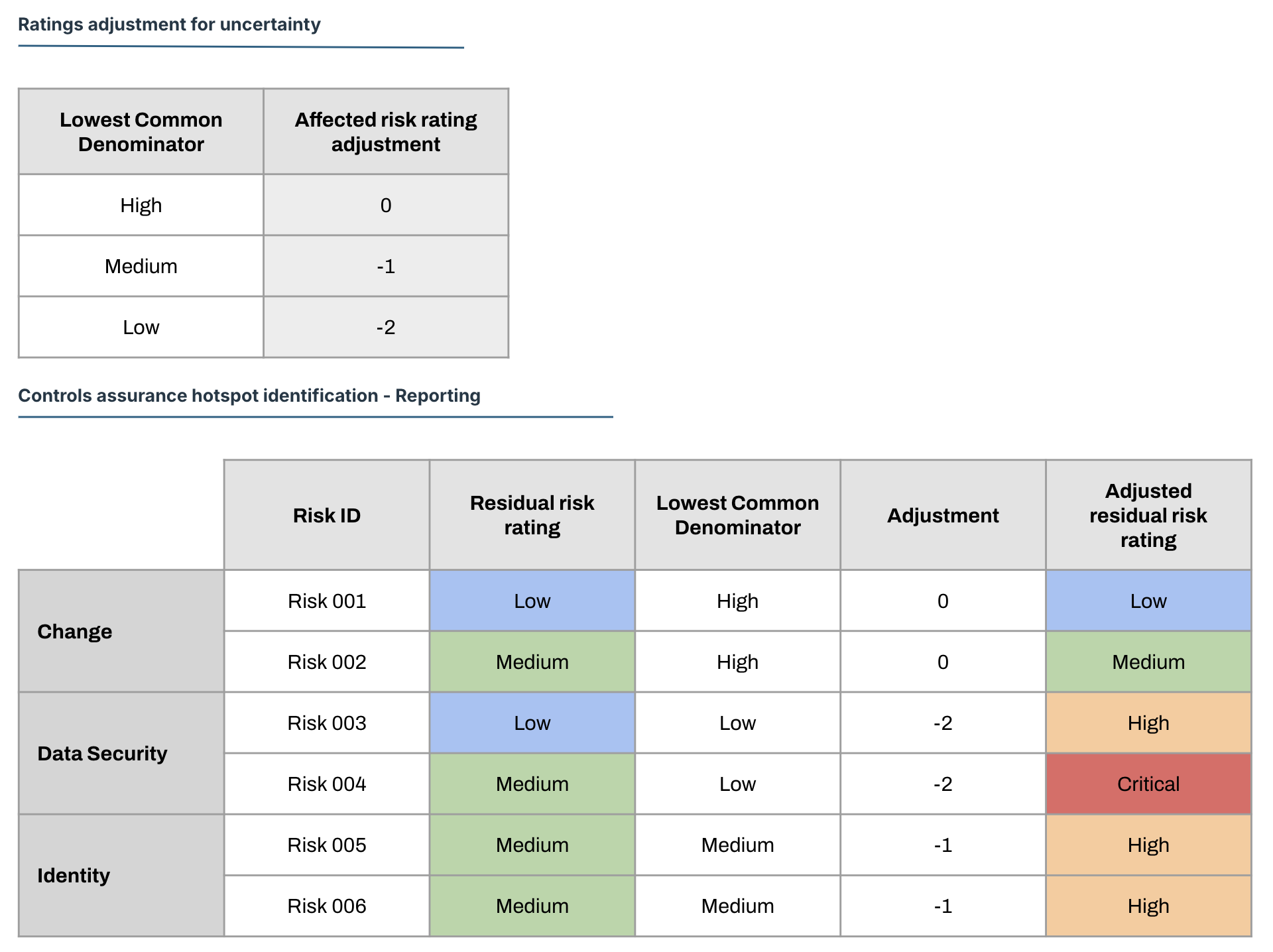
This gives us strong data to create a new projection based on adjusted residual risks and allows us to create a projection of our actual risk position that is reflective of the information we have.
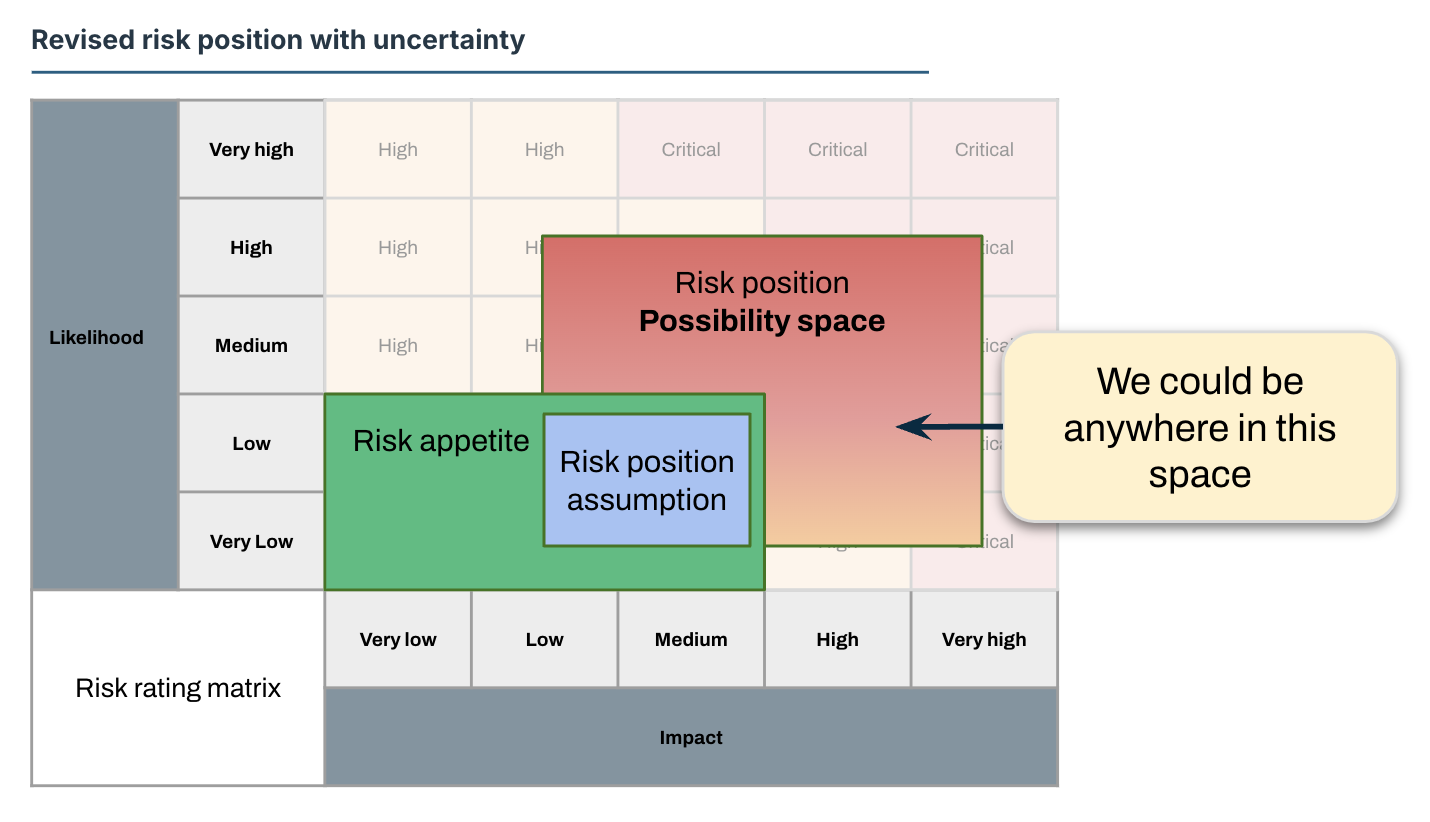
What? Have we missed anything?
Again, the answer is almost certainly yes and again, this will be a matter of degrees. My experience is that risk originates in the same distinct areas across organisations. We can apply Rumsfeld’s awareness matrix with a bit of tweaking to illustrate this.

All of the risks we’ve been working with so far are solidly in the KNOWN/KNOWN quadrant. We can place them on the map and get an idea of what our relative position is like.
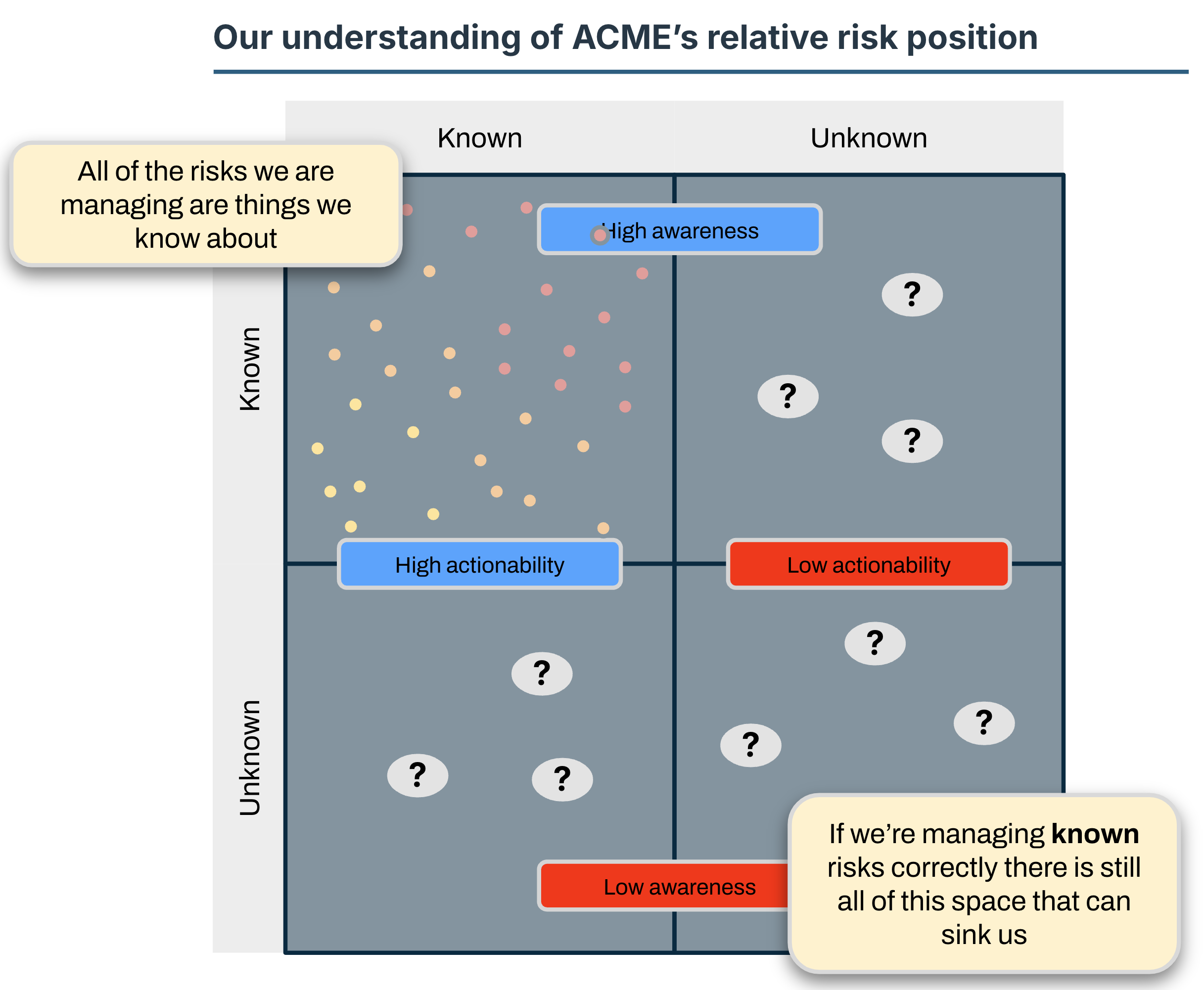
The density and distribution of UNKNOWN risks is unlikely to be similar to the KNOWN/KNOWN risks. Managing unknowns is a separate topic, but the key parts are,
- Periodic external reviews to surface
KNOWN/UNKNOWNandUNKNOWN/KNOWNrisks - Mature and tested Business Continuity Plans (BCP) and Disaster Recovery (DR) plans to guard against
UNKNOWN/UNKNOWNrisks - Financial reserves to handle unknown risk materialisation